Testes dos Algoritmos (III)
Testes para avaliar o desempenho ao fixar-se parte dos nós. Foram utilizados os mesmos conjuntos de dados da segunda parte dos testes.
Circuitos em árvore
A restrição
à jaula não foi aplicada. Os nós fixos são
referentes ao alimentador principal selecionado no algoritmo de Rao e
Deekshit. O caso de nós não colineares é gerado
através da etapa adicional de gerar pequenos deslocamentos
nestes nós.
Resultados
Primeiro Conjunto de Dados -- nós fixos colineares (36 nós)
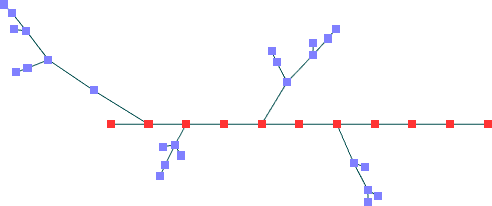
Mota:Ka=1,12 Kv=1,02
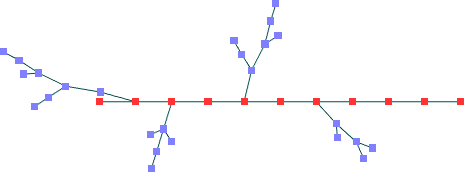
Spring Embedder
Segundo Conjunto de Dados -- nós fixos colineares (90 nós)
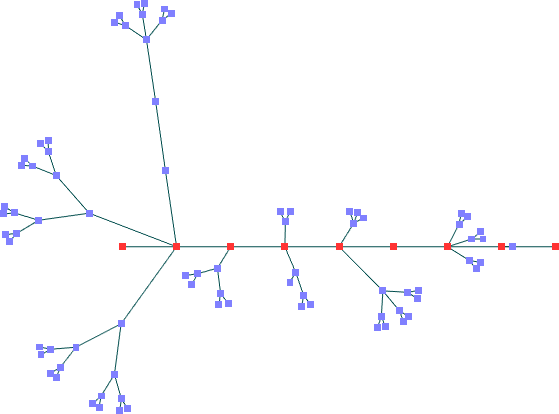
Mota:Ka=1,36 Kv=0,46
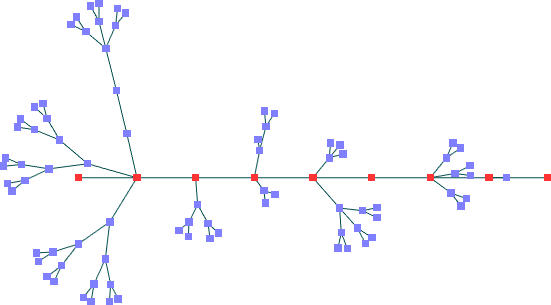
Spring Embedder
Segundo Conjunto de Dados -- nós fixos não-colineares (90 nós)
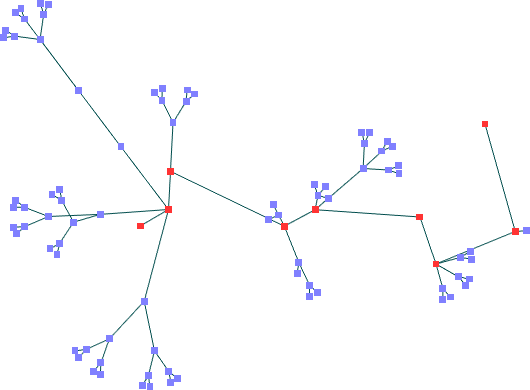
Mota:Ka=1,36 Kv=0,46
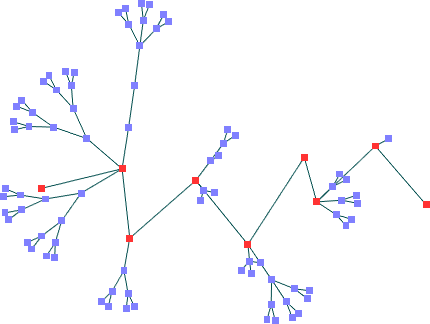
Spring Embedder
Análise dos Resultados
Para
nós colineares, os resultados são bastante
próximos. Quando não são colineares,
poderíamos avaliar o resultado do algoritmo de Mota como mais
eficiente, pois a densidade de nós não é
tão grande quanto no outro resultado. Apesar disso, os dois
algoritmos compartilham deficiências, como alguns cruzamentos.
Circuitos com partes cíclicas -- poucos (30) nós
30 nós e 40 arestas
Resultados
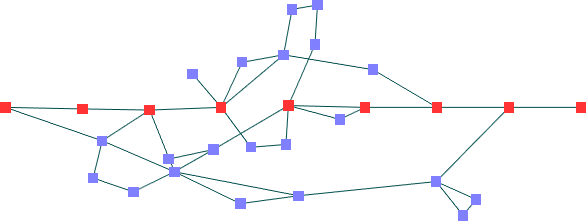
Mota: Ka = 0,57 Kv=1,50
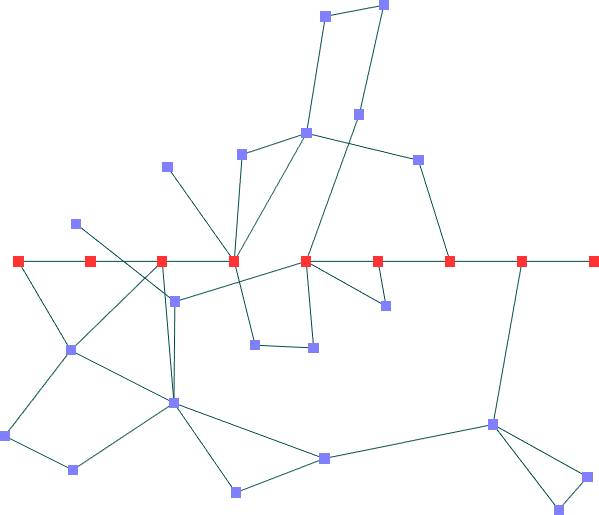
Spring Embedder
Análise dos Resultados
Este
é um dos casos onde a estrutura compacta do algoritmo de Mota
apresenta vantagens: com um conjunto pequeno de nós, é
interessante que possamos avaliar todos os nós simultaneamente.
O Spring Embedder gera uma
estrutura que ocupa mais área e também gera mais
cruzamentos para este conjunto de dados, dificultando a leitura do
diagrama.
Circuitos com partes cíclicas -- muitos (300) nós
300 nós e 411 ramos
Resultados -- nós fixos colineares
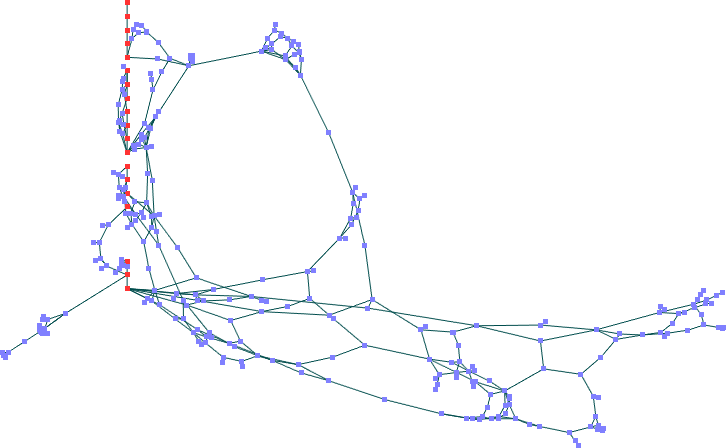
Mota

Spring Embedder
Resultados -- nós fixos em posições aleatórias
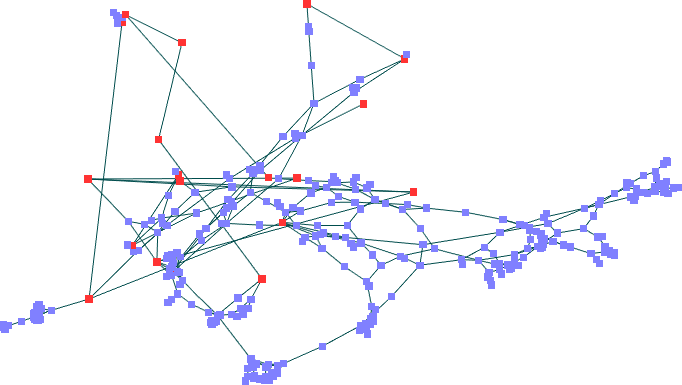
Mota
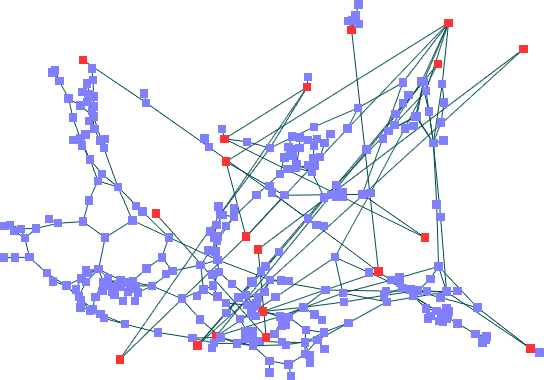
Spring Embedder
Análise dos Resultados
Quando
os nós foram colocados em posições colineares, o
comportamento do Spring Embedder não foi satisfatório. O
algoritmo de Mota, apesar de também gerar um grande
número de cruzamentos em alguns pontos próximos aos
pontos fixos, manteve as mesmas propriedades para os outros nós
de quando o conjunto de dados não continha nós fixos.
Para
o segundo caso, com nós fixos em posições
aleatórias, os resultados foram mais próximos, mas
é interessante observar que parte do diagrama manteve a forma
para o algoritmo de Mota (observe a parte à direita das
imagens), enquanto o Spring Embedder de Fruchterman gerou um
posicionamento que nada lembra o anterior, com fixos colineares.