Um algoritmo básico de ordenação é o algoritmo de ordenação pelo menor valor, que pode ser sucintamente descrito como a seguir. Inicialmente, procure a entrada que apresenta o menor valor de chave na tabela. Uma vez que seja definido que entrada é essa, troque-a com a primeira entrada da tabela. Repita então o procedimento para o restante da tabela, excluindo os elementos que já estão na posição correta. Esse procedimento é descrito no Algoritmo 2.3, que recebe como argumento a tabela a ser ordenada com base nos valores da chave de cada entrada. No procedimento, pos1 e pos2 são as posições da tabela sendo correntemente analisadas e min corresponde à posição que contém a chave com menor valor dentre as restantes na tabela. A variável sml contém o valor da menor chave encontrada.
Neste algoritmo, o laço de iteração mais externo indica o primeiro elemento na tabela não ordenada a ser analisado -- no início, esse é o primeiro elemento da tabela. As linhas de 4 a 8 são responsáveis por procurar, no restante da tabela, o elemento com menor valor de chave. Na linha 9, o procedimento auxiliar SWAP, descrito no Algoritmo 2.4, inverte o conteúdo das duas entradas nas posições especificadas.
Este tipo de algoritmo de ordenação é razoável para manipular tabelas
com um pequeno número de elementos, mas à medida que o tamanho da
tabela cresce ele passa a se tornar inviável -- sua complexidade
temporal é ![]() , conseqüência do duplo laço de iteração que
varre a tabela até o final. Felizmente, há outros algoritmos de
ordenação com melhores características.
, conseqüência do duplo laço de iteração que
varre a tabela até o final. Felizmente, há outros algoritmos de
ordenação com melhores características.
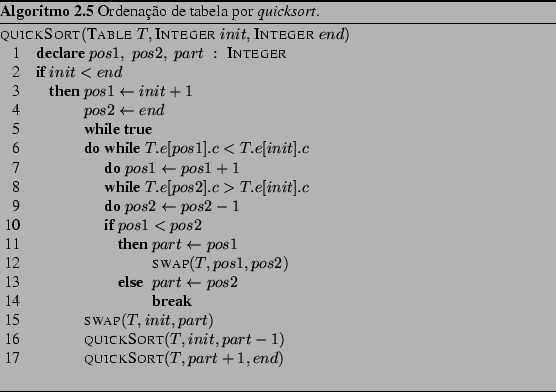
Quicksort é baseado no princípio de ``dividir para conquistar:'' o conjunto de elementos a ser ordenado é dividido em dois subconjuntos (partições), que sendo menores irão requerer menor tempo total de processamento que o conjunto total, uma vez que o tempo de processamento para a ordenação não é linear com a quantidade de elementos. Em cada partição criada, o procedimento pode ser aplicado recursivamente, até um ponto onde o tamanho da partição seja pequeno o suficiente para que a ordenação seja realizada de forma direta por outro algoritmo.
Nesta descrição do procedimento QUICKSORT (Algoritmo 2.5), os argumentos determinam as posições inicial e final do segmento da tabela a ser ordenado, init e end, respectivamente.
O segredo deste algoritmo está na forma de realizar a partição -- um elemento é escolhido como pivô, ou separador de partições. Nesse procedimento, a posição do pivô resultante é estabelecida pela posição part. Todos os elementos em uma partição têm valores menores que o valor do pivô, enquanto todos os elementos de outra partição têm valores maiores que o valor do pivô. Os dois laços internos (iniciando nas linhas 6 e 8) fazem a busca pelo pivô tomando como ponto de partida o valor inicial. Um melhor desempenho poderia ser obtido obtendo-se o valor médio de três amostras como ponto de partida para o pivô -- por exemplo, entre os valores no início, meio e fim da tabela. Dessa forma, haveria melhores chances de obter como resultado partições de tamanhos mais balanceados, característica essencial para atingir um bom desempenho para esse algoritmo.
Quicksort é um algoritmo rápido em boa parte dos casos onde
aplicado, com complexidade temporal média
![]() .
Entretanto, no pior caso essa complexidade pode degradar para
.
Entretanto, no pior caso essa complexidade pode degradar para ![]() . Mesmo assim, implementações genéricas desse algoritmo são
usualmente suportadas em muitos sistemas -- por exemplo, pela rotina
qsort da biblioteca padrão da linguagem C.
. Mesmo assim, implementações genéricas desse algoritmo são
usualmente suportadas em muitos sistemas -- por exemplo, pela rotina
qsort da biblioteca padrão da linguagem C.
Entre os principais atrativos de quicksort destacam-se o fato de que na maior parte dos casos sua execução é rápida e de que é possível implementar a rotina sem necessidade de espaço de memória adicional. Uma desvantagem de quicksort é que todos os elementos devem estar presentes na memória para poder iniciar o processo de ordenação. Isto inviabiliza seu uso para situações de ordenação on the fly, ou seja, onde o processo de ordenação ocorre à medida que elementos são definidos.
![\begin{Program}
% latex2html id marker 770
[hbt]
\begin{algorithm}{minEntrySort}...
...{algorithm}\caption{Ordenação de tabela pela busca do menor valor.}\end{Program}](img42.png)
![\begin{Program}
% latex2html id marker 794
[hbt]
\begin{algorithm}{swap}{\textsc...
...orithm}\caption{Troca de conteúdos de duas posições de uma tabela.}\end{Program}](img43.png)