|
|
|
|
|
|
|
|
|
 |
|
|
|
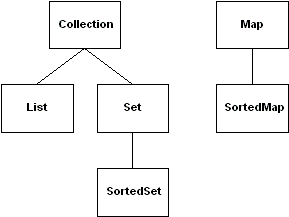
Introduction to the Collections Framework
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Interface | Implementation | Historical | |||
|---|---|---|---|---|---|
Set |
HashSet |
TreeSet |
|||
List |
ArrayList |
LinkedList |
Vector |
||
Map |
HashMap |
TreeMap |
Hashtable |
||
There are no implementations of the Collection interface. The historical collection
classes are called such because they have been around since the 1.0 release of
the Java class libraries.
If you are moving from the historical collection classes to the new framework classes, one of the primary differences is that all operations are unsynchronized with the new classes. While you can add synchronization to the new classes, you cannot remove it from the old.
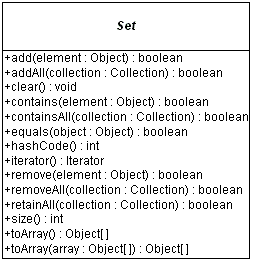
The Collection interface is used to represent any group of objects, or elements. You use the interface
when you wish to work with a group of elements in as general a manner as possible. Here is a list of the public methods of Collection in Unified Modeling Language (UML) notation.

The interface supports basic operations like adding and removing. When you try to remove an element, only a single instance of the element in the collection is removed, if present.
boolean add(Object element)boolean remove(Object element)The Collection interface also supports query
operations:
int size()boolean isEmpty()boolean contains(Object element)Iterator iterator()The iterator() method of the Collection
interface returns an Iterator. An Iterator is
similar to the Enumeration interface, which you may
already be familiar with, and will be described later. With the Iterator
interface methods, you can traverse a collection from start to
finish and safely remove elements from the underlying Collection:

The remove() method is optionally supported by the
underlying collection. When called, and supported, the element
returned by the last next() call is removed. To
demonstrate, the following shows the use of the Iterator interface for a general Collection:
Collection collection = ...;
Iterator iterator = collection.iterator();
while (iterator.hasNext()) {
Object element = iterator.next();
if (removalCheck(element)) {
iterator.remove();
}
}Other operations the Collection interface supports
are tasks done on groups of elements or the entire collection at
once:
boolean containsAll(Collection collection)boolean addAll(Collection collection)void clear()void removeAll(Collection collection)void retainAll(Collection collection)The containsAll() method allows you to discover if
the current collection contains all the elements of another
collection, a subset. The remaining methods are
optional, in that a specific collection might not support the
altering of the collection. The addAll() method ensures
all elements from another collection are added to the current
collection, usually a union. The clear() method
removes all elements from the current collection. The removeAll() method is like clear() but only removes a subset of elements. The retainAll() method is similar to the removeAll() method, but does what might be perceived as the opposite. It removes from the current collection those elements not in the other collection, an intersection.
The remaining two interface methods, which convert a Collection
to an array, will be discussed later.
The AbstractCollection class provides the basis for the concrete collection framework classes. While you are free to implement all the methods of the Collection interface yourself, the AbstractCollection class provides implementations for all the methods, except for the iterator() and size() methods, which are implemented in the appropriate subclass. Optional methods like add() will throw an exception if the subclass doesn't override the behavior.
In the creation of the Collections Framework, the Sun
development team needed to provide flexible interfaces that
manipulated groups of elements. To keep the design simple,
instead of providing separate interfaces for optional
capabilities, the interfaces define all the methods an
implementation class may provide. However, some of the
interface methods are optional. Because an interface
implementation must provide implementations for all the interface
methods, there needed to be a way for a caller to know if an
optional method is not supported. The manner the framework
development team chose to signal callers when an optional method
is called was to thrown an UnsupportedOperationException.
If in the course of using a collection, an UnsupportedOperationException
is thrown, like trying to add to a read-only collection, then the
operation failed because it is not supported. To avoid having to
place all collection operations within a try-catch
block, the UnsupportedOperationException class is an
extension of the RuntimeException class.
In addition to handling optional operations with a runtime
exception, the iterators for the concrete collection
implementations are fail-fast. That means that if you
are using an Iterator to traverse a collection while
underlying collection is being modified by another thread, then
the Iterator fails immediately by throwing a ConcurrentModificationException
(another RuntimeException). That means the next time an Iterator
method is called, and the underlying collection has been
modified, the ConcurrentModificationException exception
gets thrown.
The Set interface extends the Collection
interface and, by definition, forbids duplicates within the
collection. All the original methods are present and no new
methods are introduced. The concrete Set implementation
classes rely on the equals() method of the object added
to check for equality.
The Collections Framework provides two general-purpose
implementations of the Set interface: HashSet
and TreeSet. More often than not, you will use a HashSet
for storing your duplicate-free collection. For efficiency,
objects added to a HashSet need to implement the hashCode()
method in a manner that properly distributes the hash codes.
While most system classes override the default hashCode()
implementation in Object, when creating your own classes
to add to a HashSet remember to override hashCode().
The TreeSet implementation is useful when you need to
extract elements from a collection in a sorted manner. In order
to work property, elements added to a TreeSet must be sortable. The Collections Framework
adds support for Comparable elements
and will be covered in detail later. For now, just assume a tree
knows how to keep elements of the java.lang wrapper
classes sorted. It is
generally faster to add elements to a HashSet, then
convert the collection to a TreeSet for sorted
traversal.
To optimize HashSet space usage, you can tune the
initial capacity and load factor. The TreeSet has no
tuning options, as the tree is always balanced, ensuring log(n)
performance for insertions, deletions, and queries.
Both HashSet and TreeSet implement the Cloneable
interface.
To demonstrate the use of the concrete Set classes,
the following program creates a HashSet and adds a group
of names, including one name twice. The program than prints out
the list of names in the set, demonstrating the duplicate name
isn't present. Next, the program treats the set as a TreeSet
and displays the list sorted.
import java.util.*;
public class SetExample {
public static void main(String args[]) {
Set set = new HashSet();
set.add("Bernadine");
set.add("Elizabeth");
set.add("Gene");
set.add("Elizabeth");
set.add("Clara");
System.out.println(set);
Set sortedSet = new TreeSet(set);
System.out.println(sortedSet);
}
}Running the program produces the following output. Notice that the duplicate entry is only present once, and the second list output is sorted.
[Gene, Clara, Bernadine, Elizabeth] [Bernadine, Clara, Elizabeth, Gene]
The AbstractSet class overrides the equals()
and hashCode() methods to ensure two equal sets return
the same hash code. Two sets are equal if they are the same size
and contain the same elements. By definition, the hash code for a
set is the sum of the hash codes for the elements of the set.
Thus, no matter what the internal ordering of the sets, two equal
sets will report the same hash code.
The List interface extends the Collection
interface to define an ordered collection, permitting duplicates.
The interface adds position-oriented operations, as well as the
ability to work with just a part of the list.

The position-oriented operations include the ability to insert
an element or Collection, get an element, as well as
remove or change an element. Searching for an element in a List
can be started from the beginning or end and will report the
position of the element, if found.
void add(int index, Object element)boolean addAll(int index, Collection collection)Object get(int index)int indexOf(Object element)int lastIndexOf(Object element)Object remove(int index)Object set(int index, Object element)The List interface also provides for working with a
subset of the collection, as well as iterating through the entire
list in a position friendly manner:
ListIterator listIterator()ListIterator listIterator(int startIndex)List subList(int fromIndex, int toIndex)In working with subList(), it is important to mention
that the element at fromIndex is in the sub list, but
the element at toIndex is not. This loosely maps to the
following for-loop test cases:
for (int i=fromIndex; i<toIndex; i++) {
// process element at position i
}In addition, it should be mentioned that changes to the
sublist [like add(), remove(), and set()
calls] have an effect on the underlying List.
The ListIterator interface extends the Iterator
interface to support bi-directional access, as well as adding or
changing elements in the underlying collection.

The following source code demonstrates the looping backwards
through a list. Notice that the ListIterator is
originally positioned beyond the end of the list [list.size()],
as the index of the first element is 0.
List list = ...;
ListIterator iterator = list.listIterator(list.size());
while (iterator.hasPrevious()) {
Object element = iterator.previous();
// Process element
}Normally, one doesn't use a ListIterator to alternate
between going forward and backward in one iteration through the
elements of a collection. While technically possible, one needs
to know that calling next() immediately after previous() results in the same element being returned.
The same thing happens when you reverse the order of the calls to
next() and previous().
The add() operation requires a little bit of
explanation, also. Adding an element results in the new element
being added immediately prior to the implicit cursor. Thus,
calling previous() after adding an element would return
the new element and calling next() would have no effect,
returning what would have been the next element prior to the add
operation.
There are two general-purpose List implementations in
the Collections Framework: ArrayList and LinkedList.
Which of the two List implementations you use depends on
your specific needs. If you need to support random access,
without inserting or removing elements from any place other than
the end, than ArrayList offers the optimal collection.
If, however, you need to frequently add and remove elements from
the middle of the list and only access the list elements
sequentially then LinkedList offers the better
implementation.
Both ArrayList and LinkedList implement the Cloneable
interface. In addition, LinkedList adds several methods
for working with the elements at the ends of the list (only the
new methods are shown in the following diagram):
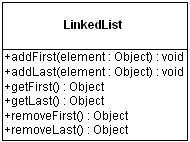
By using these new methods, you can easily treat the LinkedList
as a stack, queue, or other end-oriented data structure.
LinkedList queue = ...; queue.addFirst(element); Object object = queue.removeLast();
LinkedList stack = ...; stack.addFirst(element); Object object = stack.removeFirst();
The Vector and Stack classes are historical
implementations of the List interface. They will be
discussed later.
The following program demonstrates the use of the concrete List
classes. The first part creates a List backed by an ArrayList.
After filling the list, specific entries are retrieved. The LinkedList
part of the example treats the LinkedList as a queue,
adding things at the beginning of the queue and removing them
from the end.
import java.util.*;
public class ListExample {
public static void main(String args[]) {
List list = new ArrayList();
list.add("Bernadine");
list.add("Elizabeth");
list.add("Gene");
list.add("Elizabeth");
list.add("Clara");
System.out.println(list);
System.out.println("2: " + list.get(2));
System.out.println("0: " + list.get(0));
LinkedList queue = new LinkedList();
queue.addFirst("Bernadine");
queue.addFirst("Elizabeth");
queue.addFirst("Gene");
queue.addFirst("Elizabeth");
queue.addFirst("Clara");
System.out.println(queue);
queue.removeLast();
queue.removeLast();
System.out.println(queue);
}
}Running the program produces the following output. Notice
that, unlike Set, List permits duplicates.
[Bernadine, Elizabeth, Gene, Elizabeth, Clara] 2: Gene 0: Bernadine [Clara, Elizabeth, Gene, Elizabeth, Bernadine] [Clara, Elizabeth, Gene]
There are two abstract List implementations classes: AbstractList
and AbstractSequentialList. Like the AbstractSet
class, they override the equals() and hashCode()
methods to ensure two equal collections return the same hash
code. Two sets are equal if they are the same size and contain
the same elements in the same order. The hashCode()
implementation is specified in the List interface
definition and implemented here.
Besides the equals() and hashCode()
implementations, AbstractList and AbstractSequentialList
provide partial implementations of the remaining List
methods. They make the creation of concrete list implementations
easier, for random-access and sequential-access data sources,
respectively. Which set of methods you need to define depends on
the behavior you wish to support. The following table should help
you remember which methods need to be implemented. One thing
you'll never need to provide yourself is an
implementation of the Iterator iterator() method.
AbstractList |
AbstractSequentialList |
|
| unmodifiable | Object get(int index) |
ListIterator listIterator(int index) |
| modifiable | unmodifiable + Object set(int index, Object element) |
unmodifiable + ListIterator |
| variable-size and modifiable |
modifiable +add(int index, Object element) |
modifiable +ListIterator |
As the Collection interface documentation states, you
should also provide two constructors, a no-argument one and one
that accepts another Collection.
The Map interface is not an extension of the Collection
interface. Instead, the interface starts off its own interface
hierarchy, for maintaining key-value associations. The interface
describes a mapping from keys to values, without duplicate keys,
by definition.
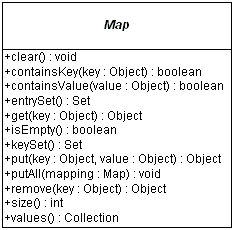
The interface methods can be broken down into three sets of operations: altering, querying, and providing alternative views.
The alteration operations allow you to add and remove
key-value pairs from the map. Both the key and value can be null.
However, you should not add a Map to itself as a key or
value.
Object put(Object key, Object value)Object remove(Object key)void putAll(Map mapping)void clear()The query operations allow you to check on the contents of the map:
Object get(Object key)boolean containsKey(Object key)boolean containsValue(Object value)int size()boolean isEmpty()The last set of methods allow you to work with the group of keys or values as a collection.
public Set keySet()public Collection values()public Set entrySet()Since the collection of keys in a map must be unique, you get
a Set back. Since the collection of values in a map may
not be unique, you get a Collection back. The last
method returns a Set of elements that implement the Map.Entry
interface, described next.
The entrySet() method of Map returns a
collection of objects that implement Map.Entry
interface. Each object in the collection is a specific key-value
pair in the underlying Map.
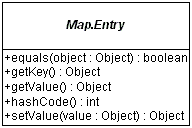
Iterating through this collection, you can get the key or
value, as well as change the value of each entry. However, the
set of entries becomes invalid, causing the iterator behavior to
be undefined, if the underlying Map is modified outside
the setValue() method of the Map.Entry
interface.
The Collections Framework provides two general-purpose Map
implementations: HashMap and TreeMap . As with
all the concrete implementations, which implementation you use
depends on your specific needs. For inserting, deleting, and
locating elements in a Map, the HashMap offers
the best alternative. If, however, you need to traverse the keys
in a sorted order, then TreeMap is your better
alternative. Depending upon the size of your collection, it may
be faster to add elements to a HashMap, then convert the
map to a TreeMap for sorted key traversal. Using a HashMap
requires that the class of key added have a well-defined hashCode()
implementation. With the TreeMap implementation,
elements added to the map must be sortable. Again, more on
sorting later.
To optimize HashMap space usage, you can tune the
initial capacity and load factor. The TreeMap has no
tuning options, as the tree is always balanced.
Both HashMap and TreeMap implement the Cloneable
interface.
The Hashtable and Properties classes are
historical implementations of the Map interface. They
will be discussed later.
The following program demonstrates the use of the concrete Map
classes. The program generates a frequency count of words passed
from the command line. A HashMap is initially used for
data storage. Afterwards, the map is converted to a TreeMap
to display the key list sorted.
import java.util.*;
public class MapExample {
public static void main(String args[]) {
Map map = new HashMap();
Integer ONE = new Integer(1);
for (int i=0, n=args.length; i<n; i++) {
String key = args[i];
Integer frequency = (Integer)map.get(key);
if (frequency == null) {
frequency = ONE;
} else {
int value = frequency.intValue();
frequency = new Integer(value + 1);
}
map.put(key, frequency);
}
System.out.println(map);
Map sortedMap = new TreeMap(map);
System.out.println(sortedMap);
}
}Running the program with the the text from Article 3 of the Bill of Rights produces the following output. Notice how much more useful the sorted output looks.
Unsorted
{prescribed=1, a=1, time=2, any=1, no=1, shall=1, nor=1,
peace=1, owner=1, soldier=1, to=1, the=2, law=1, but=1, manner=1,
without=1, house=1, in=4, by=1, consent=1, war=1, quartered=1,
be=2, of=3}
and sorted
{a=1, any=1, be=2, but=1, by=1, consent=1, house=1, in=4,
law=1, manner=1, no=1, nor=1, of=3, owner=1, peace=1,
prescribed=1, quartered=1, shall=1, soldier=1, the=2, time=2,
to=1, war=1, without=1}
Similar to the other abstract collection implementations, the AbstractMap
class overrides the equals() and hashCode()
methods to ensure two equal maps return the same hash code. Two
maps are equal if they are the same size, contain the same keys,
and each key maps to the same value in both maps. By definition,
the hash code for a map is the sum of the hash codes for the
elements of the map, where each element is an implementation of
the Map.Entry interface. Thus, no matter what the
internal ordering of the maps, two equal maps will report the
same hash code.
A WeakHashMap is a special-purpose implementation of Map
for storing only weak references to the keys. This allows for the
key-value pairs of the map to be garbage collected when the key
is no longer referenced outside of the WeakHashMap.
Using WeakHashMap is beneficial for maintaining
registry-like data structures, where the utility of an entry
vanishes when its key is no longer reachable by any thread.
The Java 2 SDK, Standard Edition, version 1.3 adds a
constructor to WeakHashMap that accepts a Map.
With version 1.2 of the Java 2 platform, the available
constructors only permit overriding the default load factor and
initial capacity setting, not initializing the map from another
map (as recommended by the Map interface documentation).
There have been many changes to the core Java libraries to add
support for sorting with the addition of the Collections
Framework to the Java 2 SDK, version 1.2. Classes like String
and Integer now implement the Comparable
interface to provide a natural sorting order. For those classes
without a natural order, or when you desire a different order
than the natural order, you can implement the Comparator
interface to define your own.
To take advantage of the sorting capabilities, the Collections
Framework provides two interfaces that use it: SortedSet
and SortedMap.
The Comparable interface, in the java.lang
package, is for when a class has a natural ordering. Given a
collection of objects of the same type, the interface allows you
to order the collection into that natural ordering.

The compareTo() method compares the current instance
with an element passed in as an argument. If the current instance
comes before the argument in the ordering, a negative value is
returned. If the current instance comes after, then a positive
value is returned. Otherwise, zero is returned. It is not a
requirement that a zero return value signifies equality of
elements. A zero return value just signifies that two objects are
ordered at the same position.
There are fourteen classes in the Java 2 SDK, version 1.2,
that implements the Comparable interface. The following
table shows their natural ordering. While some classes share the
same natural ordering, you can only sort classes that are mutually
comparable. For the current release of the SDK, that means
the same class.
| Class | Ordering |
|---|---|
BigDecimal |
Numerical |
Character |
Numerical by Unicode value |
CollationKey |
Locale-sensitive string ordering |
Date |
Chronological |
File |
Numerical by Unicode value of characters in fully-qualified, system-specific pathname |
ObjectStreamField |
Numerical by Unicode value of characters in name |
String |
Numerical by Unicode value of characters in string |
The documentation for the compareTo() method of String
defines the ordering lexicographically. What this means is the comparison is
of the numerical values of the characters in the text, which is not
necessarily alphabetically in all languages. For locale-specific ordering, use
Collator with CollationKey.
The following demonstrates the use of Collator
with CollationKey to do a locale-specific sorting:
import java.text.*;
import java.util.*;
public class CollatorTest {
public static void main(String args[]) {
Collator collator = Collator.getInstance();
CollationKey key1 = collator.getCollationKey("Tom");
CollationKey key2 = collator.getCollationKey("tom");
CollationKey key3 = collator.getCollationKey("thom");
CollationKey key4 = collator.getCollationKey("Thom");
CollationKey key5 = collator.getCollationKey("Thomas");
Set set = new TreeSet();
set.add(key1);
set.add(key2);
set.add(key3);
set.add(key4);
set.add(key5);
printCollection(set);
}
static private void printCollection(
Collection collection) {
boolean first = true;
Iterator iterator = collection.iterator();
System.out.print("[");
while (iterator.hasNext()) {
if (first) {
first = false;
} else {
System.out.print(", ");
}
CollationKey key = (CollationKey)iterator.next();
System.out.print(key.getSourceString());
}
System.out.println("]");
}
}Running the program produces the following output:
[thom, Thom, Thomas, tom, Tom]
If the names were stored directly, without using Collator,
then the lowercase names would appear apart from the uppercase
names:
[Thom, Thomas, Tom, thom, tom]
Making your own class Comparable is just a matter of
implementing the compareTo() method. It usually involves
relying on the natural ordering of several data members. Your own
classes should also override equals() and hashCode()
to ensure two equal objects return the same hash code.
When a class wasn't designed to implement java.lang.Comparable,
you can provide your own java.util.Comparator. Providing
your own Comparator also works if you don't like the
default Comparable behavior.

The return values of the compare() method of Comparator
are similar to the compareTo() method of Comparable.
In this case, if the first element comes before the second
element in the ordering, a negative value is returned. If the
first element comes after, then a positive value is returned.
Otherwise, zero is returned. Similar to Comparable, a
zero return value does not signify equality of elements. A zero
return value just signifies that two objects are ordered at the
same position. Its up to the user of the Comparator to
determine how to deal with it. If two unequal elements compare to
zero, you should first be sure that is what you want and second
document the behavior. Using a Comparator that is not
compatible to equals can be deadly when used with a TreeSet
or TreeMap. With a set, only the first will be added.
With a map, the value for the second will replace the value for
the second (keeping the key of the first).
To demonstrate, you may find it easier to write a new Comparator
that ignores case, instead of using Collator to do a
locale-specific, case-insensitive comparison. The following is
one such implementation:
class CaseInsensitiveComparator implements Comparator {
public int compare(Object element1, Object element2) {
String lowerE1 = ((String)element1).toLowerCase();
String lowerE2 = ((String)element2).toLowerCase();
return lowerE1.compareTo(lowerE2);
}
}Since every class subclasses Object at some point, it
is not a requirement that you implement the equals()
method. In fact, in most cases you won't. Do keep in mind the equals()
method checks for equality of Comparator
implementations, not the objects being compared.
The Collections class has one predefined Comparator
available for reuse. Calling Collections.reverseOrder()
returns a Comparator that sorts objects that implement
the Comparable interface in reverse order.
The Collections Framework provides a special Set
interface for maintaining elements in a sorted order: SortedSet.

The interface provides access methods to the ends of the set
as well as to subsets of the set. When working with subsets of
the list, changes to the subset are reflected in the source set.
In addition, changes to the source set are reflected in the
subset. This works because subsets are identified by elements at
the end points, not indices. In addition, if the fromElement
is part of the source set, it is part of the subset. However, if
the toElement is part of the source set, it is not part
of the subset. If you would like a particular to-element to be in
the subset, you must find the next element. In the case of a String,
the next element is the same string with a null character
appended (string+"\0").;
The elements added to a SortedSet must either
implement Comparable or you must provide a Comparator
to the constructor of its implementation class: TreeSet.
(You can implement the interface yourself. But the Collections
Framework only provides one such concrete implementation class.)
To demonstrate, the following example uses the reverse order Comparator
available from the Collections class:
Comparator comparator = Collections.reverseOrder();
Set reverseSet = new TreeSet(comparator);
reverseSet.add("Bernadine");
reverseSet.add("Elizabeth");
reverseSet.add("Gene");
reverseSet.add("Elizabeth");
reverseSet.add("Clara");
System.out.println(reverseSet);Running the program produces the following output:
[Gene, Elizabeth, Clara, Bernadine]
Because sets must hold unique items, if comparing two
elements when adding an element results in a zero return value
(from either the compareTo() method of Comparable
or the compare() method of Comparator), then
the new element is not added. If the elements are equal, then
that is okay. However, if they are not, then you should modify
the comparison method such that the comparison is compatible with
equals().
Using the prior CaseInsensitiveComparator to
demonstrate this problem, the following creates a set with three
elements: thom, Thomas, and Tom, not five elements as might be
expected.
Comparator comparator = new CaseInsensitiveComparator();
Set set = new TreeSet(comparator);
set.add("Tom");
set.add("tom");
set.add("thom");
set.add("Thom");
set.add("Thomas");The Collections Framework provides a special Map
interface for maintaining keys in a sorted order: SortedMap.
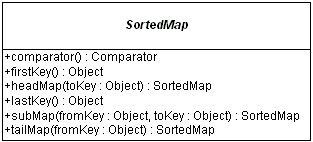
The interface provides access methods to the ends of the map
as well as to subsets of the map. Working with a SortedMap
is just like a SortedSet, except the sort is done on the
map keys. The implementation class provided by the Collections
Framework is a TreeMap.
Because maps can only have one value for every key, if
comparing two keys when adding a key-value pair results in a zero
return value (from either the compareTo() method of Comparable
or the compare() method of Comparator), then
the value for the original key is replaced with the new value. If
the elements are equal, then that is okay. However, if they are
not, then you should modify the comparison method such that the
comparison is compatible with equals().
To keep the Collections Framework simple, added
functionality is provided by wrapper implementations (also known as the
Decorator design pattern--see the Design Patterns book for more
information on patterns). These wrappers delegate the
collections part to the underlying implementation class, but they
add functionality on top of the collection. These wrappers are
all provided through the Collections class. The Collections
class also provides support for creating special-case
collections.
After you've added all the necessary elements to a collection,
it may be convenient to treat that collection as read-only, to
prevent the accidental modification of the collection. To provide
this capability, the Collections class provides six
factory methods, one for each of Collection, List,
Map, Set, SortedMap, and SortedSet.
Collection unmodifiableCollection(Collection
collection)List unmodifiableList(List list)Map unmodifiableMap(Map map)Set unmodifiableSet(Set set)SortedMap unmodifiableSortedMap(SortedMap map)SortedSet unmodifiableSortedSet(SortedSet set)Once you've filled the collection, the best way to make the collection read-only is to replace the original reference with the read-only reference. If you don't replace the original reference, then the collection is not read-only, as you can still use the original reference to modify the collection. The following program demonstrates the proper way to make a collection read-only. In addition, it shows what happens when you try to modify a read-only collection.
import java.util.*;
public class ReadOnlyExample {
public static void main(String args[]) {
Set set = new HashSet();
set.add("Bernadine");
set.add("Elizabeth");
set.add("Gene");
set.add("Elizabeth");
set = Collections.unmodifiableSet(set);
set.add("Clara");
}
}When run and the last add() operation is attempted on
the read-only set, an UnsupportedOperationException is
thrown.
The key difference between the historical collection classes
and the new implementations within the Collections Framework is
the new classes are not thread-safe. This was done such
that if you don't need the synchronization, you don't use it, and
everything works much faster. If, however, you are using a
collection in a multi-threaded environment, where multiple
threads can modify the collection simultaneously, the
modifications need to be synchronized. The Collections
class provides for the the ability to wrap existing collections
into synchronized ones with another set of six methods:
Collection synchronizedCollection(Collection
collection)List synchronizedList(List list)Map synchronizedMap(Map map)Set synchronizedSet(Set set)SortedMap synchronizedSortedMap(SortedMap map)SortedSet synchronizedSortedSet(SortedSet set)Unlike when making a collection read-only, you synchronize the collection immediately after creating it. You also must make sure you do not retain a reference to the original collection, or else you can access the collection unsynchronized. The simplest way to make sure you don't retain a reference is to never create one:
Set set = Collection.synchronizedSet(new HashSet());
Making a collection unmodifiable also makes a collection thread-safe, as the collection can't be modified. This avoids the synchronization overhead.
The Collections class provides for the ability to
create single element sets fairly easily. Instead of having to
create the Set and fill it in separate steps, you can do
it all at once. The resulting Set is immutable.
Set set = Collection.singleton("Hello");The Java 2 SDK, Standard Edition, version 1.3 adds the ability to create singleton lists and maps, too:
List singletonList(Object element)Map singletonMap(Object key, Object value)If you need an immutable list with multiple copies of the same
element, the nCopies(int n, Object element) method of
the Collections class returns just such the List:
List fullOfNullList = Collection.nCopies(10, null);
By itself, that doesn't seem too useful. However, you can then make the list modifiable by passing it along to another list:
List anotherList = new ArrayList(fullOfNullList);
This now creates 10 element ArrayList, where each
element is null. You can now modify each element at
will, as it becomes appropriate.
The Collections class also provides constants for
empty collections:
List EMPTY_LISTSet EMPTY_SETThe Java 2 SDK, Standard Edition, version 1.3 has a predefined empty map constant:
Map EMPTY_MAPWhile this course is about the new Collections Framework of the Java 2 SDK, there are times when you still need to use some of the original collections capabilities. The following reviews some of the capabilities of working with arrays, vectors, hashtables, enumerations, and other historical capabilities.
One learns about arrays fairly early on when learning the Java programming language. Arrays are defined to be fixed-size collections of the same datatype. They are the only collection that supports storing primitive datatypes. Everything else, including arrays, can store objects. When creating an array, you specify both the number and type of object you wish to store. And, over the life of the array, it can neither grow nor store a different type (unless it extends the first type).
To find out the size of an array, you ask its single public
instance variable, length, as in array.length.
To access a specific element, either for setting or getting,
you place the integer argument within square brackets ([int]),
either before or after the array reference variable. The
integer index is zero-based, and accessing beyond either end of
the array will thrown an ArrayIndexOutOfBoundsException
at runtime. If, however, you use a long variable to
access an array index, you'll get a compiler-time error.
Arrays are full-fledged subclasses of java.lang.Object.
They can be used with the various Java programming language
constructs excepting an object:
Object obj = new int[5];
if (obj instanceof int[]) {
// true
}
if (obj.getClass().isArray()) {
// true
}When created, arrays are automatically initialized, either to false
for a boolean array , null for an Object
array, or the numerical equivalent of 0 for everything else.
To make a copy of an array, perhaps to make it larger, you use
the arraycopy() method of System. You need to
preallocate the space in the destination array.
System.arraycopy(Object sourceArray, int
sourceStartPosition, Object destinationArray, int
destinationStartPosition, int length)A Vector is an historical collection class that acts
like a growable array, but can store heterogeneous data elements.
With the Java 2 SDK, version 2, the Vector class has
been retrofitted into the Collections Framework hierarchy to
implement the List interface. However, if you are using
the new framework, you should use ArrayList, instead.
When transitioning from Vector to ArrayList,
one key difference is the arguments have been reversed to
positionally change an element's value:
Vector class
void setElementAt(Object element, int index)List interface
void set(int index, Object element)The Stack class extends Vector to implement
a standard list-in-first-out (LIFO) stack, with push()
and pop() methods. Be careful though. Since the Stack
class extends the Vector class, you can still access or
modify a Stack with the inherited Vector
methods.
The Enumeration interface allows you to iterator
through all the elements of a collection. In the Collections
Framework, this interface has been superceded by the Iterator
interface. However, not all libraries supports the newer
interface, so you may find yourself using Enumeration
from time to time.

Iterating through an Enumeration is similar to
iterating through an Iterator, though some people like
the method names better with Iterator. However, there is
no removal support with Enumeration.
Enumeration enum = ...;
while (enum.hasNextElement()) {
Object element = iterator.nextElement();
// process element
}The Dictionary class is completely full of abstract
methods. In other words, it should have been an interface. It
forms the basis for key-value pair collections in the historical
collection classes, with its replacement being Map, in
the new framework. Hashtable and Properties are
the two specific implementations of Dictionary
available.
The Hashtable implementation is a generic dictionary
that permits storing any object as its key or value (besides null).
With the Java 2 SDK, version 1.2, The class has been reworked
into the Collections Framework to implement the Map
interface. So, when using, you can use the original Hashtable
methods or the newer Map methods. If you need a
synchronized Map, using Hashtable is slightly
faster than using a synchronized HashMap.
The Properties implementation is a specialized Hashtable
for working with text strings. While you have to cast valued
retrieved from a Hashtable to your desired class, the Properties
class allows you to get text values without casting. The class
also supports loading and saving property settings from and input
stream or to a output stream. The most commonly used set of
properties is the system properties list, retrieved by System.getProperties().
A BitSet represents an alternate representation of a
set. Given a finite number of n objects, you can
associate a unique integer with each object. Then each possible
subset of the objects corresponds to an n-bit vector,
with each bit "on" or "off" depending on
whether the object is in the subset. For small values of n
a bit vector might be an extremely compact representation.
However, for large values of n an actual bit vector
might be inefficient, when most of the bits are off.
There is no replacement to BitSet in the new
framework.
The Collections and Arrays classes,
available as part of the Collections Framework, provide support
for various algorithms with the collection classes, both new and
old. The different operations, starting with sorting and
searching, are described next.
While the TreeSet and TreeMap classes offer
sorted version of sets and maps, there is no sorted List
collection implementation. Also, prior to the collections
framework, there was no built in support for sorting arrays. As
part of the framework, you get both support for sorting a List,
as well as support for sorting arrays of anything, including
primitives. With any kind of sorting, all items must be
comparable to each other (mutually comparable). If they
are not, a ClassCastException will be thrown.
Sorting of a List is done with one of two sort()
methods in the Collections class. If the element type
implements Comparable then you would use the sort(List
list) version. Otherwise, you would need to provide a Comparator
and use sort(List list, Comparator comparator). Both
versions are destructive to the List and guarantee O(n
log2n) performance (or better),
including when sorting a LinkedList, using a merge sort
variation.
Sorting of arrays is done with one of eighteen different
methods. There are two methods for sorting each of the seven
primitive types (besides boolean), one for sorting the
whole array and one for sorting part of the array. The remaining
four are for sorting object arrays (Object[ ]).
The sorting of primitive arrays involving just calling Arrays.sort()
with your array as the argument, and letting the compiler
determine which of the following methods to pick:
void sort(byte array[ ])void sort(byte array[ ], int fromIndex, int toIndex)void sort(short array[ ])void sort(short array[ ], int fromIndex, int toIndex)void sort(int array[ ])void sort(int array[ ], int fromIndex, int toIndex)void sort(long array[ ])void sort(long array[ ], int fromIndex, int toIndex)void sort(float array[ ])void sort(float array[ ], int fromIndex, int toIndex)void sort(double array[ ])void sort(double array[ ], int fromIndex, int
toIndex)void sort(char array[ ])void sort(char array[ ], int fromIndex, int toIndex)The sorting of object arrays is a little more involved, as the
compiler doesn't check everything for you. If the object in the
array implements Comparable, then you can just sort the
array directly, in whole or in part. Otherwise, you must provide
a Comparator to do the sorting for you. You can also
provide a Comparator implementation if you don't like
the default ordering.
void sort(Object array[ ])void sort(Object array[ ], int fromIndex, int
toIndex)void sort(Object array[ ], Comparator comparator)void sort(Object array[ ], int fromIndex, int
toIndex, Comparator comparator)Besides sorting, the Collections and Arrays
classes provide mechanisms to search a List or array, as
well as to find the minimum and maximum values within a Collection.
While you can use the contains() method of List
to find if an element is part of the list, it assumes an unsorted
list. If you've previously sorted the List, using Collections.sort(),
then you can do a much quicker binary search using one of the two
overridden binarySearch() methods. If the objects in the
List implement Comparable, then you don't need
to provide a Comparator. Otherwise, you must provide a Comparator.
In addition, if you sorted with a Comparator, you must
use the same Comparator when binary searching.
public static int binarySearch(List list, Object key)public static int binarySearch(List list, Object key,
Comparator comparator)If the List to search subclasses the AbstractSequentialList
class (like LinkedList), then a sequential search is
actually done.
Array searching works the same way. After using one of the Arrays.sort()
methods, you can take the resulting array and search for an
element. There are seven overridden varieties of binarySearch()
to search for a primitive (all but boolean), and two to
search an Object array, both with and without a Comparator.
If the original List or array is unsorted, the result
is non-deterministic.
Besides searching for specific elements within a List,
you can search for extreme elements within any Collection:
the minimum and maximum. If you know your collection is already
sorted, just get the first or last element. However, for unsorted
collections, you can use one of the min() or max()
methods of Collections. If the object in the collection
doesn't implement Comparable, then you must provide a Comparator.
Object max(Collection collection)Object max(Collection collection, Comparator
comparator)Object min(Collection collection)Object min(Collection collection, Comparator
comparator)While the MessageDigest class always provided an isEqual()
method to compare two byte arrays, it never felt right
to use it to compare byte arrays unless they were from
message digests. Now, with the help of the Arrays class,
you can check for equality of any array of primitive or object
type. Two arrays are equal if they contain the same elements in
the same order. Checking for equality with arrays of objects
relies on the equals() method of each object to check
for equality.
byte array1[] = ...;
byte array2[] = ...;
if (Arrays.equals(array1, array2) {
// They're equal
}The Collections and Arrays classes offer
several ways of manipulating the elements within a List
or array. There are no additional ways to manipulate the other
key framework interfaces (Set and Map).
With a List, the Collections class lets you
replace every element with a single element, copy an entire list
to another, reverse all the elements, or shuffle them around.
When copying from one list to another, if the destination list is
larger, the remaining elements are untouched.
void fill(List list, Object element)void copy(List source, List destination)void reverse(List list)void shuffle(List list)void shuffle(List list, Random random)The Arrays class allows you to replace an entire
array or part of an array with one element via eighteen
overridden versions of the fill() method. All the
methods are of the form fill(array, element) or fill(array,
fromIndex, toIndex, element).
Performance of sorting and searching operations with
collections of size n is measured using Big-O notation.
The notation describes the complexity of the algorithm in
relation to the maximum time in which an algorithm operates, for
large values of n. For instance, if you iterate through
an entire collection to find an element, the Big-O notation is
referred to as O(n), meaning that as n
increases, time to find an element in a collection of size n
increases linearly. This demonstrates that Big-O notation assumes
worst case performance. It is always possible that performance is
quicker.
The following table shows the Big-O values for different operations, with 65,536 as the value for n. In addition, the operation count shows that if you are going to perform multiple search operations on a collection, it is faster to do a quick sort on the collection, prior to searching, versus doing a linear search each time. (And, one should avoid bubble sorting, unless n is really small!)
| Description | Big-O | # Operations | Example |
|---|---|---|---|
| Constant | O(1) | 1 | Hash table lookup (ideal) |
| Logarithmic | O(log2n) | 16 | Binary search on sorted collection |
| Linear | O(n) | 65,536 | Linear search |
| Linear-logarithmic | O(n log2n) | 1,048,576 | Quick sort |
| Quadratic | O(n2) | 4,294,967,296 | Bubble sort |
| Legend: n = 65536 | |||
The Collections Framework was designed such that the new framework classes and the historical data structure classes can interoperate. While it is good if you can have all your new code use the new framework, sometimes you can't. The framework provides much support for intermixing the two sets of collections. In addition, you can develop with a subset of the capabilities with JDK 1.1.
There are convenience methods for converting from many of the
original collection classes and interfaces to the newer framework
classes and interfaces. They serve as bridges when you need a new
collection but have an historical collection. You can go from an
array or Vector to a List, a Hashtable
to a Map, or an Enumeration to any Collection.
For going from any array to a List, you use the asList(Object
array[]) method of the Arrays class. Changes to the
List pass through to the array, but you cannot adjust
the size of the array.
String names[] = {"Bernadine",
"Elizabeth", "Gene", "Clara"};
List list = Arrays.asList(names);Because the original Vector and Hashtable
classes have been retrofitted into the new framework, as a List
and Map respectively, there is no work to treat either of
these historical collections as part of the new framework.
Treating a Vector as a List automatically
carries to its subclass Stack. Treating a Hashtable
as a Map automatically caries to its subclass Properties.
Moving an Enumeration to something in the new
framework requires a little more work, as nothing takes an Enumeration
in its constructor. So, to convert an Enumeration, you
create some implementation class in the new framework and add
each element of the enumeration.
Enumeration enumeration = ...;
Collection collection = new LinkedList();
while (e.hasMoreElements()) {
collection.add(e.nextElement());
}
// Operate on collectionIn addition to supporting the use of the old collection
classes within the new collection framework, there is also
support for using the new framework and still using libraries
that only support the original collections. You can easily
convert from Collection to array, Vector, or Enumeration,
as well as from Map to Hashtable.
There are two ways to go from Collection to array,
depending upon the type of array you need. The simplest way
involves going to an Object array. In addition, you can
also convert the collection into any other array of objects.
However, you cannot directly convert the collection into an array
of primitives, as collections must hold objects.
To go from a collection to an Object[], you use the toArray()
method of Collection:
Collection collection = ...; Object array[] = collection.toArray();
The toArray() method is overridden to accept an array
for placing the elements of the collection: toArray(Object
array[]). The datatype of the argument determines the type
of array used to stored the collection and returned by the
method. If the array isn't large enough, a new array of the
appropriate type will be created.
Collection collection = ...; int size = collection.size(); Integer array[] = collection.toArray(new Integer[size]);
To go from Collection to Vector, the Vector
class now includes a constructor that accepts a Collection.
As with all these conversions, if the element in the original
conversion is mutable, then no matter from where it is retrieved
and modified, its changed everywhere.
Dimension dims[] = {new Dimension (0,0),
new Dimension (0,0)};
List list = Arrays.asList(dims);
Vector v = new Vector(list);
Dimension d = (Dimension)v.get(1);
d.width = 12;Going from Collection to Enumeration is much
easier than going from Enumeration to Collection.
The Collections class includes a static method to do the
conversion for you:
Collection collection = ...; Enumeration enum = Collections.enumeration(collection);
The conversion from Map to Hashtable is
similar to Collection to Vector, just pass the
new framework class to the constructor. After the conversion,
changing the value for the key in one does not alter the value
for the key in the other.
Map map = ...; Hashtable hashtable = new Hashtable(map);
If you are still using JDK 1.1, you can start taking advantage
of the Collections Framework today. Sun Microsystems provides
a subset of the collections API for use with JDK 1.1. The
interfaces and classes of the framework have been moved from the java.lang
and java.util package to the non-core com.sun.java.util.collections
package. This is not a complete set of classes changed to support
the framework, but only copies of those introduced. Basically,
what that means is none of the system classes are sortable by
default, you must provide your own Comparator.
The following table lists the classes available in the
Collections Framework release for JDK 1.1. In some cases, there
will be two different implementations of the same class, like
with Vector, as the 1.2 framework version implements List
and the core 1.1 version doesn't.
AbstractCollection |
AbstractList |
AbstractMap |
AbstractSequentialList |
AbstractSet |
ArrayList |
Arrays |
Collection |
Collections |
Comparable |
Comparator |
ConcurrentModificationException |
HashMap |
HashSet |
Hashtable |
Iterator |
LinkedList |
List |
ListIterator |
Map |
NoSuchElementException |
Random |
Set |
SortedMap |
SortedSet |
TreeMap |
TreeSet |
UnsupportedOperationException |
Vector |
Because the Collection Framework was not available prior to the introduction of the Java 2 platform, several alternative collection libraries became available. Two such libraries are Doug Lea's Collections Package and ObjectSpace's JGL.
The collections package from Doug Lea (author of Concurrent Programming in Java), was first available in October 1995 and last updated in April 1997. It probably offered the first publicly available collections library. While no longer supported, the library shows the complexity added to the class hierarchy when you try to provide updateable and immutable collections, without optional methods in interfaces or wrapper implementations. While a good alternative at the time, its use is no longer recommended. (Doug also helped author some of the Collections Framework.)
In addition to Doug Lea's collections library, the Generic Collection Library for Java (JGL) from ObjectSpace was an early collection libraries available for the Java platform. Following the design patterns of the Standard Template Library (STL) for C++, the library provides algorithmic support, in addition to a data structure library. While the JGL is a good alternative collection framework, it didn't meet the design goals of the Collections Framework team: "The main design goal was to produce an API that was reasonably small, both in size, and, more importantly, in conceptual weight." With that in mind, the team came up with the Collections Framework.
While not adopted by Sun Microsystems, the JGL has been included with many IDE tool. Due to its early availability, the JGL is available to well over 100,000 developers.
For a comparison of JGL versus the Collections Framework, see The battle of the container frameworks: which should you use? article in JavaWorld. [If you are curious of how the library name maps to the acronym, it doesn't. The name of the first version of the library infringed on Sun's Java trademark. ObjectSpace changed the name, but the original acronym stuck.]
The Collections Framework provides a well-designed set of interfaces, implementations, and algorithms for representing and manipulating groups of elements. Understanding all the capabilities of this framework reduces the effort required to design and implement a comparable set of APIs, as was necessary prior to their introduction. Now that you have completed this module, you can effectively manage groups of data elements.
The following resources, some pulled from the course notes, should help in your usage and understanding of the Collections Framework:
Copyright © 1999 MageLang Institute. All Rights Reserved.