O analisador de deslocamento e redução trabalha com duas estruturas de dados auxiliares, além da tabela de deslocamento e redução. A primeira delas é a lista de símbolos terminais a analisar, que contém inicialmente a sentença submetida à análise delimitada ao final pelo símbolo $. A outra estrutura é uma pilha com os símbolos já analisados, os quais podem ter sido eventualmente substituídos por símbolos não-terminais pela aplicação de produções da gramática. Portanto, a pilha pode conter qualquer símbolo, terminal ou não-terminal, do alfabeto da gramática.
Há dois principais procedimentos auxiliares utilizados nesse
algoritmo. O primeiro é NEXTACTION(), que determina qual a
próxima ação em função do estado corrente do analisador e da consulta
à tabela de deslocamento e redução. Seus argumentos são, além da
referência à gramática, um símbolo que corresponde ao topo da pilha e
o próximo símbolo da sentença. Seu valor de retorno foi definido ser
do tipo Action, que pode assumir os valores ![]() ,
, ![]() ,
,
![]() ou o valor nulo para indicar uma situação de erro.
ou o valor nulo para indicar uma situação de erro.
O outro procedimento auxiliar usado na descrição do algoritmo é REDUCE(), que recebe como argumentos a referência à gramática e à pilha. Esse procedimento retira do topo da pilha os símbolos que podem ser utilizados para combinar, na ordem correta, com o lado direito da produção aplicável no estado atual. Seu valor de retorno é o símbolo resultante, aquele do lado esquerdo da produção aplicada.
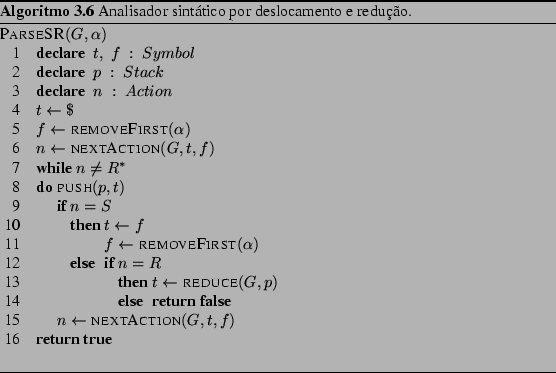
O Algoritmo 3.6, que descreve o procedimento do
analisador, recebe como argumentos a descrição da gramática ![]() e a
lista
e a
lista ![]() com a sentença a ser analisada. O valor de retorno é
verdadeiro, se a sentença pertence à gramática, ou falso, caso
contrário.
com a sentença a ser analisada. O valor de retorno é
verdadeiro, se a sentença pertence à gramática, ou falso, caso
contrário.
A aplicação desse algoritmo é ilustrada através do reconhecimento da
sentença
![]() . No estado inicial, a pilha está vazia
e
. No estado inicial, a pilha está vazia
e ![]() contém todos os símbolos da sentença:
contém todos os símbolos da sentença:
Antes do início da primeira iteração, ![]() recebe o delimitador $ e
recebe o delimitador $ e
![]() recebe o primeiro símbolo da sentença:
recebe o primeiro símbolo da sentença:
Para esses valores de ![]() e
e ![]() , a ação associada é de
deslocamento (S). Assim, na primeira iteração o símbolo em
, a ação associada é de
deslocamento (S). Assim, na primeira iteração o símbolo em ![]() é inserido no topo da pilha e os demais símbolos são deslocados, isto
é,
é inserido no topo da pilha e os demais símbolos são deslocados, isto
é, ![]() recebe o valor de
recebe o valor de ![]() e
e ![]() recebe o primeiro elemento de
recebe o primeiro elemento de
![]() .
.
Novamente, para esses valores de ![]() e
e ![]() a ação é de
deslocamento, que leva a
a ação é de
deslocamento, que leva a
A entrada na tabela de deslocamento e redução para ![]() ,
pesquisada pelo procedimento NEXTACTION(), indica
que a ação é de redução. Assim, no início da iteração o estado da
pilha é modificado (isso é independente do tipo de ação):
,
pesquisada pelo procedimento NEXTACTION(), indica
que a ação é de redução. Assim, no início da iteração o estado da
pilha é modificado (isso é independente do tipo de ação):
O valor de ![]() permanece inalterado; assim, os argumentos para o
procedimento NEXTACTION() correspondem à chave
permanece inalterado; assim, os argumentos para o
procedimento NEXTACTION() correspondem à chave ![]() ,
que novamente leva a uma redução para a próxima iteração. As
iterações prosseguem da mesma forma até que a condição de
reconhecimento seja alcançada; se a sentença fosse inválida, o
algoritmo terminaria no momento em que não houvesse uma ação aplicável
para os valores de
,
que novamente leva a uma redução para a próxima iteração. As
iterações prosseguem da mesma forma até que a condição de
reconhecimento seja alcançada; se a sentença fosse inválida, o
algoritmo terminaria no momento em que não houvesse uma ação aplicável
para os valores de ![]() e
e ![]() .
.
O processo de reconhecimento dessa sentença, partindo do estado inicial até alcançar o estado de aceitação da sentença, é apresentado na Tabela 3.4.
Métodos de análise ascendente são quase sempre determinísticos, mas há situações em que o analisador deve decidir entre dois possíveis movimentos. Uma delas é a situação de conflito reduzir ou deslocar e a outra, quando pelo menos duas regras são aplicáveis em uma situação de redução, é a situação de conflito reduzir ou reduzir.
O método LR de análise é o mais geral que pode ser aplicado a todas as linguagens e gramáticas passíveis de análise determinística. Seu nome deriva-se do fato de que a análise é realizada a partir de uma leitura dos símbolos da esquerda para a direita (Left to right) e que a derivação canônica mais à direita é obtida (Rightmost derivation).
Uma gramática LR(![]() ), usada como base de um analisador ascendente, é uma
na qual as situações de conflito podem ser resolvidas pela verificação dos
símbolos já lidos até o momento e pela visão de uma quantidade limitada a
no máximo
), usada como base de um analisador ascendente, é uma
na qual as situações de conflito podem ser resolvidas pela verificação dos
símbolos já lidos até o momento e pela visão de uma quantidade limitada a
no máximo ![]() símbolos adiante (o chamado lookahead).
símbolos adiante (o chamado lookahead).
Na prática, o valor de ![]() é geralmente limitado a 0 ou 1 sem perda de
generalidade na aplicação do método. Embora haja gramáticas LR(2) que não
são gramáticas LR(1), há um resultado teórico que diz que toda linguagem
gerada por uma gramática LR(
é geralmente limitado a 0 ou 1 sem perda de
generalidade na aplicação do método. Embora haja gramáticas LR(2) que não
são gramáticas LR(1), há um resultado teórico que diz que toda linguagem
gerada por uma gramática LR(![]() ) pode ser também gerada por uma gramática
LR(1).
) pode ser também gerada por uma gramática
LR(1).