![]()
![]()
|
|
![]()
|
Ricardo R. Gudwin |
||
|
|
||
Main Definition |
||
|
Computational Semiotics refers to the attempt of emulating the semiosis cycle within a digital computer. Among other things, this is done aiming for the construction of autonomous intelligent systems able to perform intelligent behavior, what includes perception, world modeling, value judgement and behavior generation. There is a claim that most part of intelligent behavior should be due to semiotic processing within autonomous systems, in the sense that an intelligent system should be comparable to a semiotic system. Mathematically modeling such semiotic systems is being currently the target for a group of researchers studying the interactions encountered between semiotics and intelligent systems. The key issue on this study is the discovery of elementary, or minimum units of intelligence, and their relation to semiotics. Some attempts have been made aiming for the determination of such elementary units of intelligence, i.e., a minimum set of operators that would be responsible for building intelligent behavior within intelligent systems. These attempts include Albus' outline for a theory of intelligence [1] and Meystel's GFACS algorithm [2]. Within Computational Semiotics, we try to depict the basic elements composing an intelligent system, in terms of its semiotic understanding. We do this by the definition of a knowledge unit, from which we derive a whole taxonomy of knowledge. Knowledge units, from different types and behaviors, are mathematically described, and used as atomic components for an intelligent system. They are at the same time, containers of information and active agents on the processing of such information. |
||
|
|
||
Knowledge Units |
||
|
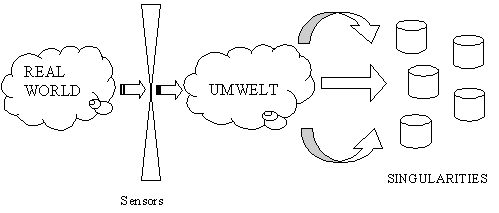
There are many attempts to define what would be the exact semantics for the term "knowledge", what would be the difference between "knowledge" and "information", and what would be the elementary pieces of knowledge, sometimes called knowledge units. We provide our own definition: "A Knowledge Unit is a granule of information encoded into a structure". The exact understanding of such definition needs some philosophical background, to be provided in the following paragraphs. First of all, we consider the existence of an environment, or real world, which is defined as a set of dynamic continuous phenomena running in parallel. We assume we are not able to know this environment in its whole. The part of environment we are able to know, in a process that goes through our sensors, is called our Umwelt [3]. The Umwelt, also called our sensible environment, is our best possible comprehension of reality. It is very important to stress, though, that Umwelt is not reality. It comprises only our best understanding of reality. In this sense, our sensors are the primary source of information that flows into our mind. These sensors do provide a continuous and partial information about phenomena occurring in Umwelt. From this continuous source of information, we extract what we call singularities, i.e., clusters of information that can be aggregated under a single concept. These singularities are discrete entities that model, in a specific level of resolution, the phenomena occurring in the world. We can also view these singularities as an intensional definition for what we are calling here knowledge units (figure 1).
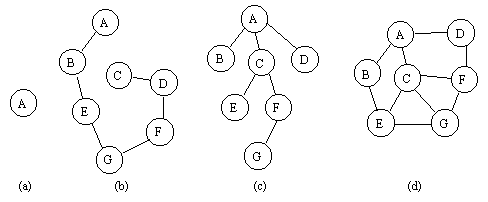
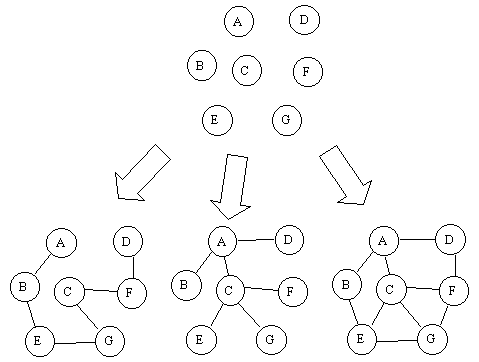
Once those granules of information (singularities) are identified in the Umwelt, they need to be encoded to become a knowledge unit (as given by our original definition). This codification needs a representation space and an embodiment vehicle (structure) that is placed within the representation space. These structures may be abstracted to mathematical structures (figure 2), i.e., (a) numbers, (b) lists, (c) trees and (d) graphs.
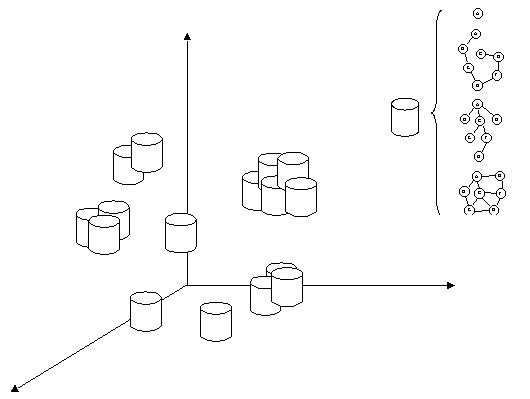
Figure 2 – Mathematical Structures Each structure has a place at the representation space (figure 3).
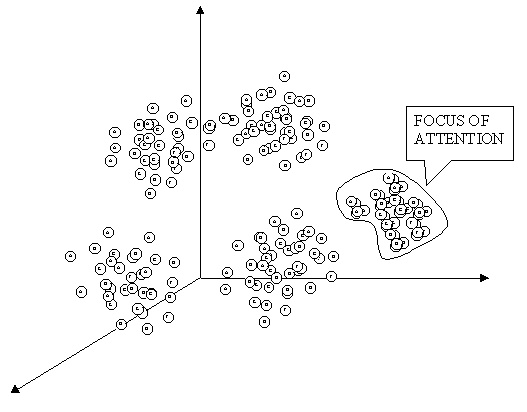
Figure 3 – Representation Space The view shown in figure 3 is though, our view of representation space after an interpretation. Before interpretation, the representation space is more like in figure 4: a set of values occupying a place in space. To build a knowledge unit, then, we need what we call a "focus of attention" mechanism, which selects a closed region of representation space, that is our primary field of interpretation.
Figure 4 – Focus of Attention and Structures Identification |
||
|
Then comes what we call the first interpretation problem, (illustrated in figure 5). How a set of values embraced by the focus of attention is going to be interpreted ? This is called the structural identification problem.
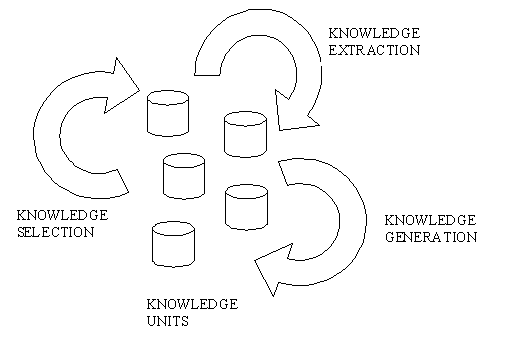
Figure 5 – Interpretation Problem A second interpretation problem, that comes once we identified the structure within our focus of attention, is related with the semantic identification of information within the structure. If the data represented by the structure respects to a direct modeling of an environment phenomenon, this knowledge unit is called an icon. If it gives the localization within the representation space of another structure, it is called an index. And, if it is a key in a conversion table, it is a symbol. In this case, we will need to use the conversion table (that should be another structure in the representation space), in order to locate the icon representing the phenomenon we want to refer to. Elementary knowledge units are formed due to these singularity extraction mechanisms. More elaborate knowledge units, though, are formed by the application of knowledge processing operators, illustrated in figure 6.
Figure 6 – Knowledge Processing Operators These knowledge processing operators are from 3 basic types, that we are going to call here generalized deduction, generalized induction and generalized abduction. We are going to address them in the following sections. |
||
|
|
||
A Taxonomy for Knowledge Units |
||
|
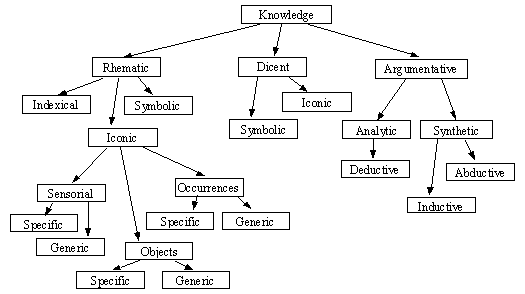
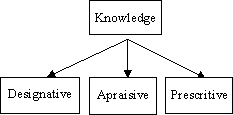
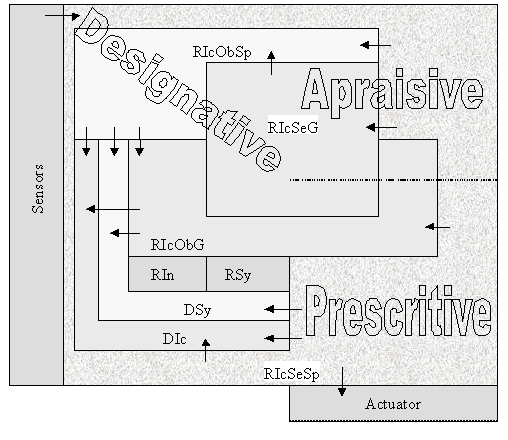
Knowledge units can be classified according to a taxonomy of types of knowledge [4,5,6,7]. This taxonomy is inspired on the classification of different types of signs, given by Peirce, and the different dimensions for an interpretant, by Morris. Peirce’s semiotics introduced a signical taxonomy, where different kinds of signs (e.g. rhemes, dicents, arguments, icons, indexes, symbols, qualisigns, sinsigns, legisigns) were proposed, addressing different characteristics of its structure and signic function. Morris identified 3 possible dimensions for an interpretant (designative, appraisive and prescriptive). The ideas from Peirce and Morris were unified in order to generate this taxonomy for knowledge units. Basically, each type of knowledge is associated with a different kind of concept (or idea), that is, the semantic that is intrinsic to a given knowledge type. We may have passive and active knowledge types. The types referred as rhematic and dicent [4,5,6,7] are passive, in the sense that they only exist as data. The knowledge types known as arguments are active. They are active in the sense that they do not only exist as data, but also performs transformations in the system. A direct analogy of passive and active types is the classification of information within a computer memory as data and code. Passive types are just like data in a computer memory. Active types are like code in a computer memory. They can be seen as data or code, depending on the context being analyzed. Active knowledge units are the primary source of activity in a semiotic system. They are responsible for the extraction of singularities and also for the further discovery and manipulation of new knowledge units within the semiotic system. Two taxonomies were developped. The first one, concerning the nature of knowledge, and the second one, concerning its pragmatical use in the construction of an intelligent system. They are presented in figures 7 and 8 below.
Figure 7 - Knowledge Units classified by its Nature
Figure 8 - Knowledge Units classified by its use in an Intelligent System These taxonomies were unified and summarized, as in figure 9. In this figure, we adopt the following convention: R means Rhematic;
Figure 9 - A Summary for Knowledge Units All arrows refer to argumentative knowledge (both analytic and synthetic). The notation between brackets is used to specify the different kinds of knowledge. For example, {RIcSeG} means a rhematic iconic sensorial generic knowledge. In this summary view, a passive knowledge unit is both classified according to its functionality (designative, apraisive, prescriptive) and to its structure (rhematic, dicent). Argumentative knowledge units are a special case, given its active characteristic, being classified both as functional and structural. |
||
|
|
Rhematic knowledge |
|
|
A rhematic ({R}) knowledge is the semantic that can be assigned to isolated words in a natural language. They concern what is usually called a semantic memory of an intelligent system. Usually, it is associated to a representation of environmental phenomena like sensorial experiences, objects and events. Sensorial experiences can be represented e.g. by adjectives, objects by substantives and events by verbs. In a last analysis, though, all of them are connected to perceptual data. The rhematic knowledge can be represented by an icon (rhematic iconic - {RIc}), a name (rhematic symbolic - {RSy}), or an index (rhematic indexical - {RIn}). A {RIc} knowledge is a direct model for the phenomenon it represents. A {RSy} knowledge is a name that refers the phenomenon. A {RIn} knowledge is an indirect reference to the phenomenon. The {RIc} knowledge can be divided into three different classes: sensorial - {RIcSe}, usually modeled by adjectives; Those three pieces of knowledge can be divided into two classes: specific (Sp) and generic (G). For example, a {RIcSe} knowledge is a sensorial information like an image or a temperature sensor measuring. A {RIcSeSp} knowledge is a particular instance of a sensorial pattern, e.g. a specific image, or the temperature in a given time. A {RicSeG} knowledge is a generic knowledge of all time occurrences of some sensorial input. The knowledge that the outside temperature is 28 degrees Celsius is a specific sensorial knowledge but the knowledge of what is a high temperature is a generic sensorial knowledge. The {RIcO}knowledge is the knowledge related to a real world object (existent or nonexistent). The {RIcOSp} knowledge is the knowledge of a specific occurrence of a specific object. It assumes an existence of an object model. This model is a {RIcOG} knowledge. The {RIcOc} knowledge corresponds to the semantic of verbs. Usually, it associates an attribute to an object, or model the changes in one or more attributes in the object (or objects) as an effect of time. E.g. the property of an object of having a color, it’s creation or destruction, etc. The {RIcOcSp} knowledge is related to a specific occurrence in time, e.g. the knowledge that a traffic light, in a specific time changed from red to green. The {RIcOcG} knowledge is related to a generic occurrence, e.g., the change of a traffic light from red to green, without specifying a particular instance. |
||
|
|
Dicent knowledge |
|
|
The dicent ({D}) knowledge is a proposition. It is used to compose what is called an episodic memory in an intelligent system. The difference of a proposition and a term is that the proposition has a truth-value associated with it. Usually, this truth-value represents the belief of the proposition and it can vary from false to true using a multivalored logic or not (e.g. fuzzy logic). Compared to rhematic knowledge, we would say that if a rhematic knowledge represents the meaning of a single word in a natural language, dicent knowledge represents the semantic of phrases in a natural language. A proposition is formed to the association of a term (or a set of terms) to a truth value. Propositions can also be formed by the association of more primitive propositions, linked by logical connectives. Examples: the knowledge that "A" is true; the knowledge that "AÙ B" is false; the knowledge that "IF AÙ B THEN C" is true. A dicent knowledge can be iconic ({DIc}) or symbolic ({DSy}). The {DSy} knowledge is a name for a whole phrase, and consequently, has attached a truth value, e.g., a label for a first order logic sentence. The {DIc} knowledge explicits its composing rhematic pieces of knowledge, associating to them a measure of the belief of this phenomenon occurrence. |
||
|
|
Designative knowledge |
|
|
Designative knowledge is used to model the world in which the intelligent system is imersed. For this purpose it uses rhematic and dicent knowledge units, either specific or generic. Designative knowledge can also be viewed as descriptive knowledge. An intelligent system initially has just a few, or eventually no designative knowledge "a priori". Usually designative knowledge emerges from the interaction between the system and world. |
||
|
|
Apraisive knowledge |
|
|
Apraisive knowledge is a type of knowledge used as an evaluation, a judgment, a criteria to measure the success in achieving goals. In natural systems, apraisive knowledge is closely related with the essential goals of a being; reproduction, survival of the individual, survival of the specie, increasing knowledge about the world, for example. Depending on the goal, it assumes special forms like: desire, repulse, fear, anger, hate, love, pleasure, pain, confort, disconfort, etc. Essentially, apraisive knowledge evaluates if a given sensation, object, or occurrence is good or not, as far as goal achievement is concerned. An apraisive knowledge is usually classified as rhematic iconic. Appraisive knowledge integrates what is called the "Value System" of an intelligent system, being associated with a large sort of emotions an intelligent system may be able to feel. These "emotions" are just an intrinsic representation for the objectives of the intelligent system. |
||
|
|
Prescriptive knowledge |
|
|
Prescriptive knowledge is intended to act on the world. Basically, prescriptive knowledge is used to establish and to implement plans through actuators. However, prescriptive knowledge will not necessarily end up with an action. Prescriptive knowledge may also be used to do predictions, but only one of them is selected to generate an action. Strictly speaking, prescriptive knowledge are commands, used to plan, predict and actuate in the real world through actuators. In the same manner of apraisive knowledge the prescriptive knowledge is usually classified as rhematic iconic. |
||
|
|
Argumentative knowledge |
|
|
Argumentative knowledge is related to the knowledge of knowledge processing and transformation. It may be seen as an algorithm that creates or transforms knowledge units within a knowledge space. It comprises both a structural and functional classification. It is structural in the sense that it is a knowledge unit just like any rhematic or dicent knowledge but its structure holds a sort of program code beyond its data. It is functional because it has an explicit functional role. A good metaphor for understanding what an argumentative knowledge is, is the representation of machine instructions within a computer memory. Those instructions can be seen both as data (a sequence of bytes) and code (processor instructions). In the same way, argumentative knowledge is both data (structure) and code (process). The argumentative knowledge ({Ar}) can be synthetic ({ArSt}) or analytic ({ArAn}). An {ArAn} knowledge unit is like a piece of code that creates new knowledge units that does not contain any new information - it only turns explicit an information that was implicit in the knowledge space. In other words, it only performs an "analysis" of existing knowledge units, making explicit something that was modeled into a more compact form. The most important {ArAn} is the "modus ponens". Different from the {ArAn}, the {ArSt} knowledge creates knowledge units that contain new information. In other words, it synthesizes new knowledge content. There are two kinds of {ArSt}: inductive ({ArStId}) and abductive ({ArStAb}). The {ArStId} knowledge makes small modifications in the premises knowledge units to produce a new one. In this sense, one can say that it is a constructive argument. One example of {ArStId} is the generalization. The {ArStAb} selects candidate units as true or false (at any degree) according to the pre-existent knowledge units in the knowledge space. The candidate units can be generated either by an {ArStId} knowledge or by any random method. Different of the {ArStId} knowledge, it is a destructive argument. |
||
|
|
||
The Knowledge of Knowledge Processing |
||
|
Active knowledge units, as pointed above, are special types classified into the knowledge hierarchy within a particular branch, involving the family of argumentative knowledge units. Opposed to passive knowledge units, they carry the property of being able to process other knowledge units. Basically, an argumentative knowledge unit is a piece of knowledge whose semantic is the understanding of knowledge manipulation. In other words, it indicates how to produce new pieces of knowledge, taking as input a set of knowledge units. In next sections, we will analyze more deeply the nature of argumentative knowledge units. Their behavior is based on a set of three basic operators, namely knowledge extraction, knowledge generation and knowledge selection, that should be understood as generalizations for the deduction, induction and abduction reasoning methods respectively. In this sense, knowledge extraction is viewed as an abstraction for deduction, knowledge generation is an abstraction for induction and knowledge selection is an abstraction for abduction, leading us to universal operators of generalized deduction, generalized induction and generalized abduction. Before going one to the study of these three knowledge operators, we have though to first discuss the issues of generalization and specialization. |
||
|
|
||
Generalization and Specialization |
||
|
Knowledge units from some types of knowledge can be compared to each other by means of an "abstraction" partial order relation ( |
||
|
|
||
The Elementary Knowledge Operators |
||
|
We propose a minimum set of operators as a conceptual basis for the construction of intelligent systems. These are the "knowledge extraction" operator, "knowledge generation" operator and "knowledge selection" operator. In fact, they are not exactly operators, but classes of operators. |
||
|
|
Knowledge Extraction |
|
|
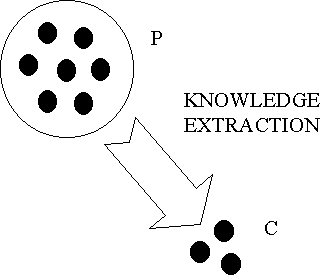
Suppose a knowledge unit b and a knowledge unit a, such that a
Figure 7 – Knowledge Extraction In figure 7 we have an example of knowledge extraction. From a set P of knowledge units, called the "premise", the operator extracts a set C of knowledge units, called the "conclusion". We call this operation knowledge extraction, because the extensional definition of the knowledge units in C is a subset of the extensional definition of knowledge units in P. So, it "extracts" from P only part of its semantic content. |
||
|
|
Knowledge Generation |
|
|
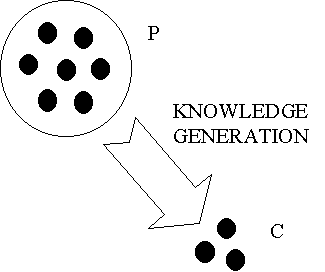
Suppose now the same a and b above, and also a function fkg that maps a onto b, i.e.,b = fkg(a). Then fkg is called a knowledge generation operator. Usually, this kind of operator is not single input/single output, but comprises a set of input knowledge units and a corresponding set of output knowledge units. Then, we have e.g. that (b1,...,bm) = fkg(a1,a2,...,an).
Figure 8 – Knowledge Generation In figure 8, the premise P is the collection of knowledge units ai and the conclusion C is the collection of knowledge units bi. One of the particularities of this operator is that the extensional definition of the knowledge units in C necessarily contains elements that are not originally in the extensional definition of knowledge units in P. They have been added during the process of knowledge generation. This is what characterizes the knowledge generation operation. This process can be done in many different ways, including combination of knowledge units, fusion of knowledge units, transformation of knowledge units (including insertion of noise), interpolation, fitting and topologic expansion of knowledge units or any hybridism of these techniques. A lot of examples may be set here. For example, the interpolation of functions adds all the points surrounding the original samples. The fitting of functions neither requires the inclusion of sample points. Topologic expansion from a number to a fuzzy number, adds all the points in the vicinity of it. The learning algorithm of a neural network transforms a set of weights describing a nonlinear classifying function into another, by adjusting it in order to include new sample points. |
||
|
|
Knowledge Selection |
|
|
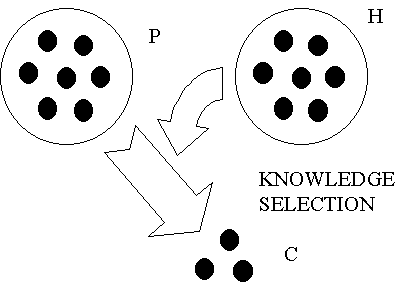
Suppose now, that we have a set of input knowledge units, {a1,a2,...,an}, and a set of candidates {c1,c2,...,cm} for being the output. Suppose also a function fks, that performs the selection among the candidates: b = fks(a1,a2,...,an,c1,c2,...,cm), in the sense that b is one of the ci's, and the ai's are used to evaluate and choose among the ci's. Then, fks is called a knowledge selection operator
Figure 9 – Knowledge Selection In figure 9, the knowledge units ai are within set P (Premise) and the ci’s are within set H, also called set of hypothesis. The knowledge units bi’s (more than one, in this case), are selected among the ci’s, and are indicated by C (Conclusion). Notice that there is a special case when there is only one ci in H, and then the selection becomes a "validation". In this case, the knowledge units in P are used to validate the new knowledge unit being output at C. In this sense, if they are not able to validate ci, it produces nothing as output. |
||
|
|
||
Implementing Knowledge Units |
||
|
|
||
References |
||
|
||
|
|
||
Interesting Links |
||
|
|
||
|
|
||