Um programa assembly é tipicamente composto por pelo menos dois segmentos, um segmento de dados que define o espaço associado ao armazenamento das variáveis e constantes usadas pelo programa; e um segmento de instruções, onde o código do programa é armazenado. Além dessas duas seções, um programa-fonte assembly pode conter uma seção de definições, usadas na descrição dos programas e que não produzem nenhum efeito no código gerado.
Por conveniência da leitura do código fonte, a seção de definições é tradicionalmente alocada ao início do código. Assim, quando o código for lido por um ser humano ele terá noção do significado das constantes simbólicas usadas ao longo do programa. Com relação aos segmentos de dados e de instruções, não há um posicionamento fixo. Na prática, um programa pode ter vários segmentos associados.
Para o montador, o posicionamento dos diferentes trechos de programa
no código fonte deve ser irrelevante. Na verdade, é necessário que o
montador seja capaz de manipular representações simbólicas antes que
elas tenham sido definidas. Considere o seguinte exemplo de um trecho
de programa:
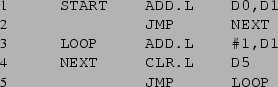
Na linha 2 desse trecho de programa há uma referência a um símbolo, NEXT, cujo valor ainda não havia sido determinado -- essa definição só acontecerá na linha 4. Há duas possibilidades de lidar com essas referências futuras.
A primeira possibilidade é deixar uma lacuna reservada no código gerado associada ao operando da instrução da linha 2. Posteriormente, quando houvesse uma definição desse valor -- provavelmente quando o fim do arquivo com o código fonte fosse alcançado -- essa lacuna seria preenchida. Neste caso, seria possível gerar o código de máquina realizando um único passo (uma única leitura) sobre o arquivo. Entretanto, haveria um maior custo na complexidade de implementação do montador, que deveria manter referências a todas as lacunas que devem ser preenchidas ao final da montagem.
A outra possibilidade, conceitualmente mais simples, é realizar o processo montagem em dois passos. O primeiro passo simplesmente lê o arquivo com o objetivo de criar a Tabela de Símbolos, ou seja, obter os valores associados a todas as constantes simbólicas definidas no programa. No segundo passo, uma nova leitura sobre o arquivo é realizada para gerar o código de máquina; nesse passo, a informação da tabela de símbolos criada no primeiro passo é utilizada.